
Observe the image below:

It is hard to see more than three at the same time. The dots keep switching place as you move your eyes through the image. When I saw this for the first time, I immediately tried to come up with a way to “follow” the dots.
Hold your closed hand as a telescope and, adjusting your little finger, try seeing one dot at a time. How many can you count?It is an odd idea the fact that our brain is telling us a different story than what is going on in the outside world. At the end of this post I will mention the two current theories to explain this optical illusion.
There have been many news about the current success of A.I. programs performing image classification and description. It is A.I., for instance, that allows Google Images to return such good results in our searches. However, we can wonder if there is any image that would fool an A.I, or that would lead the A.I. program to make a “strange mistake”. In the sense of the optical illusion we just saw, a tweaked image that is created to fool the human who sees it. This leads us to the following question:
Could we fool an A.I. with an optical illusion?
The short answer is: yes, but the mistakes made by A.I. are completely different than ours. A.I. is fascinating in itself, but as I will try to show, A.I. programs have a shallow notion of the images and its mistakes are completely different than ours.
As a first step we can present this image to a powerful A.I. system and see what happens. In the image below, I present the results from Google’s computer vision system.

We can see that the A.I. system is capable of providing relevant data about the image, but nothing in the ways of answering questions such as “how many black dots do you see”, or “the black dots keep moving!”. This system is not built to answer to these kinds of question, but to classify and categorise images.
There are other A.I. systems that are trained specifically to generate sentences that describe images (captioning systems). Unfortunately, the website I would use to demonstrate this seems not to be working properly (http://deeplearning.cs.toronto.edu/i2t), but I provide two examples below which were pre-processed by the website and chosen randomly by me¹:
-

Images taken from: http://www.cs.toronto.edu/~nitish/nips2014demo/index.html. The image on the left got the caption: “a light shines in a tower of an old , stone building.”. The image on the right: “an outdoor group of people strolling in the village”.
Both the dot illusion and the captioning examples represent the state-of-the-art in computer vision, an area that has a big intersection with A.I. We can get good results (albeit imperfect) in highly specific tasks. In this case, generating class names or captions for an image. However, we should not expect an A.I. program to answer questions for which it was not trained.
Our current A.I. systems are not built for (and could not) get close to the complexity involved in human answers when presented to the same image. For instance, the system ignored the boy doing gymnastics in the bar: this would certainly draw the attention of most humans describing the picture.
It is part of our commonsense the fact that the boy should be present in the image description. Current A.I. lacks commonsense reasoning, which is taken as one of the most important problems that separates us from true A.I. In the future I will dedicate a post just for commonsense reasoning.
After seeing a few examples of A.I.’s current capabilities, let us turn our eyes to the question of “optical illusion” for A.I. The image below represents something very curious that has been happening in computer vision:

The image on the right is obtained by combining the image on the left with the middle one. The A.I. classified the left image as a school bus and the right one as an ostrich. Image obtained from [1].
You may not notice any difference, but for the A.I. program each image is from a totally different class. The authors came up with a way to perturb the image so as to fool the program. The perturbation is the image in the middle, which for us looks like noise. This “optical illusion” is called in the literature adversarial example and was discovered in the context of research in Deep Learning, the technique responsible for much of the current A.I. boom.
Deep leaning is an inter sting technique that allows us to train a program by showing it pairs of image and its corresponding label(s). The important part is that this technique demands a lot of examples to perform as well as it does: for the school bus example, the deep learning program was trained with 1.2 millions of examples from 1000 different classes. The images for training come from ImageNet (http://www.image-net.org) and there is an yearly international competition [4].
Here I call this mistake an optical illusion together with Rodney Brooks [2]. However, this does not mean that the program in [1] is “seeing” in the same way as we do, or even that it should make the same mistakes. On the contrary, the system makes mistakes that in principle are very strange for us humans. What is interesting is how a small perturbation in an image can lead the system to give a complete different answer.
Adversarial examples are one of the most important problems in current A.I. For example, they present a serious problem for face recognition, image classification, autonomous driving, future service robots, among others.
Hackers could in principle tweak images to fool the A.I. or take control. Researchers showed that is possible to alter an image, print it and then show it to a camera and still fool the A.I. [12]. This way, hackers could carry false images in their pockets or phones and show them to cameras, cars and robots.
You can see the optical illusion with printed images in the video below:
Notice that even when showing the three indistinguishable images in the end, the program still gets it wrong by thinking that the last image is a switch. Research in adversarial examples is growing rapidly and is a great challenge for current A.I. The reason why they exist is still a matter for debate among researchers [5].
Adversarial examples lead us to thinking how a system is representing images and classes internally. We could think that the mistake occurs because of an engineering problem, a bug, but current research leads us to believe that it is an intrinsic problem in deep learning [8]. It is important to note that (1) for each image, there are many surrounding adversarial examples that can be created via perturbation, but (2) an adversarial example is an image that would hardly occur naturally.
Remember: in as much as the adversarial example is very similar to the original image (for us humans), the computer does not sense an image like we do. It sees images as a list of numbers. In the future, I will write a post about how the computer “sees” the world.
Adversarial examples do not occur only in computer vision applications, but also in A.I.s for autonomously playing games [10], or in A.I.s that learn to convert sound into text [11]. These are all evidence for adversarial examples being a much deeper problem, existing not only in images, but in other forms of input.
If you want to dive deeper and get to know ore about adversarial examples, this is a great place to start: https://blog.xix.ai/how-adversarial-attacks-work-87495b81da2d
Now let us go back to the human world. The first image of this post is an example of scintillating grid illusion. There are tow theories that try to explain it [6]: lateral inhibition and S1-type cells. The first theory states that the problem is in the neural networks in the retina itself when processing the light that enters our eyes: what happens is that a lateral inhibition process leads the neurons that are more active to inhibit less active adjacent neurons. The second theory suggests that the illusion happens deeper, in the visual cortex, with the S1-type cells that deal with image orientation.
A different but related example of how our brain fills in sensor data is the so called blind spot in our eyes. Observe the image below, following the instructions in the caption. If you are on your mobile, please turn it sideways to visualise the image in full screen.
-
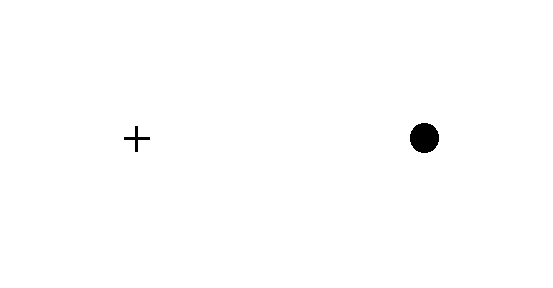
In order to “visualise” your blind spot: Close your left eye, fix your attention of your right eye on the cross; then slowly move your head closer and away form the image until the circle dot on the right disappears. Keep your attention on the cross at all times and avoid turning the eye to the circle dot, but try to merely notice it is vanishing.
Both our eyes have a blind spot, an area in the retina where photo-receptors do not exist because nervous fibre group there before going to the cortex.
Our brain deals with this blind spot by filling in the missing information with data coming from another sensor (the other eye) and surrounding areas.

There are many types of sensory illusions, not only optical [7]. Sensory illusions on top of being fun also make us reflect on how the brain works and its integration of information coming from our senses. Not only illusions, but also lack of information (as in the blind spot) obliges our brain to come up with explanations in order to understand reality.
In an A.I. program, strange responses to sensory illusion also exist and provide us with insights into how the program is internally representing knowledge. As A.I. gets more and more complex, it become necessary to user ever more indirect methods to better comprehend it. On top of that, sensory illusions that will affect future robots will possibly be very different to the ones that affect us. It would be a great challenge to understand the internal world of the robots [2].
To reflect:
1) Current A.I. is fascinating, but it is far away from being anything like the way humans can interpret images;
2) A mistake, or strange behaviour, can a lot of times be informative and generate research ideas and interesting lines of thought;
3) Sensory illusions are evidence that there is a distance between the external world and our internal mental world. This leads us to see the brain nor as a passive mainframe, but as an active agent, trying to make sense of the senses.
Notes
¹ I generated two random number between 1 and 10 and picked the corresponding images (first and sixth of the website’s pre-processed examples).
² Post featured image taken from: https://pixabay.com/en/future-eye-robot-eye-machine-175620/
Acknowledgements
To everyone who criticised and gave feedback to make this a better post.
Bonus
An interesting example about sensor integration can be seen in the McGurk effect. Watch the video below and try to identify the spoken word in each of the three movie clips:
The audio is the same in all three clips. Our brain has to choose on an internal representation in order to make sense of the dissonance between the visual and auditory inputs.
References
[1] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. and Fergus, R., 2013. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199.
[2] https://rodneybrooks.com/what-is-it-like-to-be-a-robot/
[3] Krizhevsky, A., Sutskever, I. and Hinton, G.E., 2012. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
[4] Olga Russakovsky*, Jia Deng*, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg and Li Fei-Fei. (* = equal contribution) ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015
[5] Gilmer, J., Metz, L., Faghri, F., Schoenholz, S.S., Raghu, M., Wattenberg, M. and Goodfellow, I., 2018. Adversarial Spheres. arXiv preprint arXiv:1801.02774.
[6] Schiller, P.H. and Carvey, C.E., 2005. The Hermann grid illusion revisited. Perception, 34(11), pp.1375-1397.
[7] https://www.britannica.com/topic/illusion
[8] http://serendip.brynmawr.edu/bb/latinhib.html
[9] Gilmer, J., Metz, L., Faghri, F., Schoenholz, S.S., Raghu, M., Wattenberg, M. and Goodfellow, I., 2018. Adversarial Spheres. arXiv preprint arXiv:1801.02774.
[10] https://blog.openai.com/adversarial-example-research/
[11] Carlini, N. and Wagner, D., 2018. Audio Adversarial Examples: Targeted Attacks on Speech-to-Text. arXiv preprint arXiv:1801.01944.
[12] Kurakin, A., Goodfellow, I. and Bengio, S., 2016. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533.
[13] Ninio, J. and Stevens, K.A., 2000. Variations on the Hermann grid: an extinction illusion. Perception, 29(10), pp.1209-1217.

{kind=link}
1 comentário